
I am a final-year Ph.D. candidate in the Department of Electronic Engineering and Information Science, University of Science and Technology of China, supervised by Prof. Hongtao Xie. Before that, I graduated from the School of Artificial Intelligence, Xidian University with a bachelor’s degree. My research interest includes multimodal digital human synthesis, motion generation, and face-swapping.
🔥 News
- 2025.07: 🎉🎉 One paper is accepted by Neurocomputing 2025.
- 2025.06: 🎉🎉 Two papers is accepted by ICCV 2025.
- 2025.02: 🎉🎉 Two papers is accepted by CVPR 2025.
- 2025.01: 🎉🎉 One paper is accepted by Computer Graphics Forum 2025.
- 2024.09: 🎉🎉 One paper is accepted by NeurIPS 2024.
- 2024.09: 🎉🎉 One paper is accepted by TMM 2024.
- 2024.08: 🎉🎉 One paper is accepted by CVIU 2024.
- 2024.07: 🎉🎉 One paper is accepted by SIGGRAPH Asia 2024.
📝 Publications
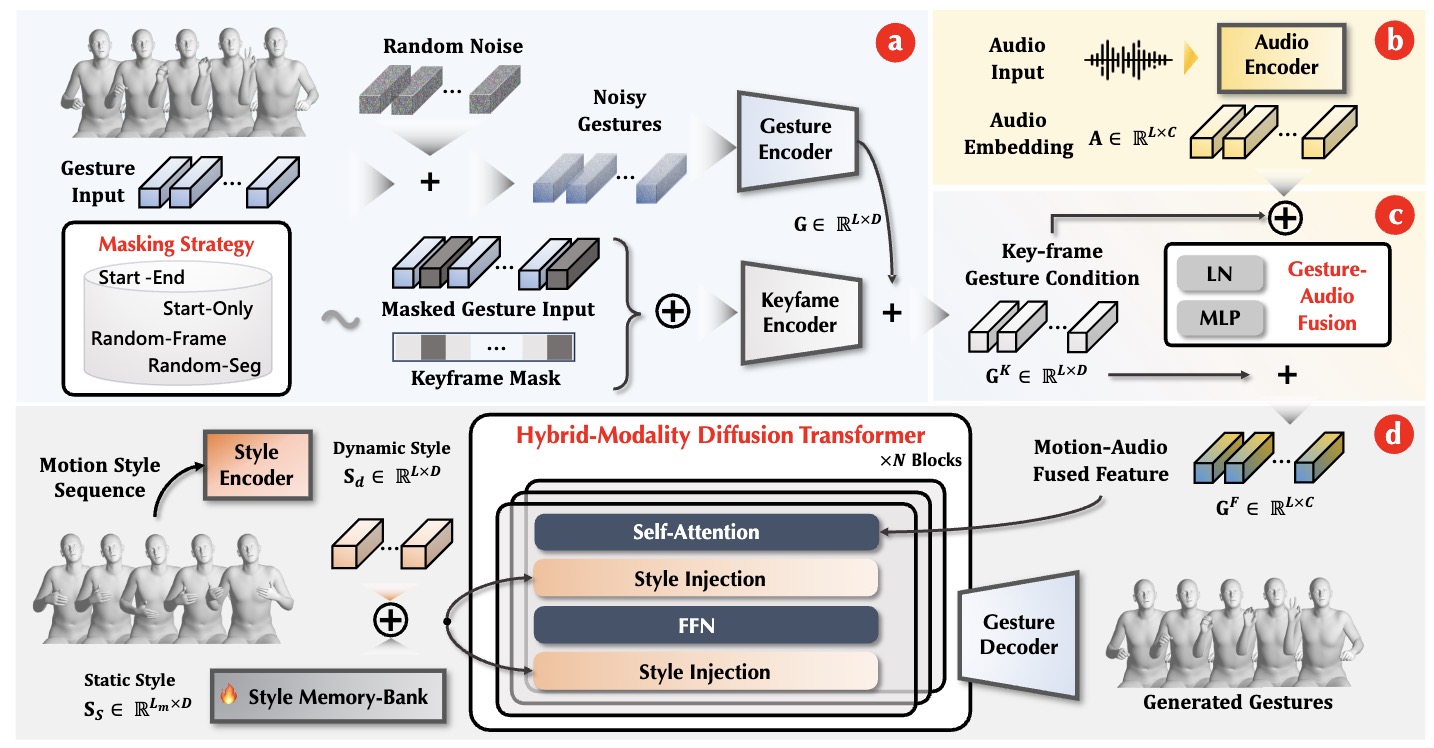
GestureHYDRA: Semantic Co-speech Gesture Synthesis via Hybrid Modality Diffusion Transformer and Cascaded-Synchronized Retrieval-Augmented Generation
Quanwei Yang*, Luying Huang*, Kaisiyuan Wang, Jiazhi Guan, Shengyi He, Fengguo Li, Lingyun Yu, Yingying Li, Haocheng Feng, Hang Zhou, Hongtao Xie.(*Equal contribution)
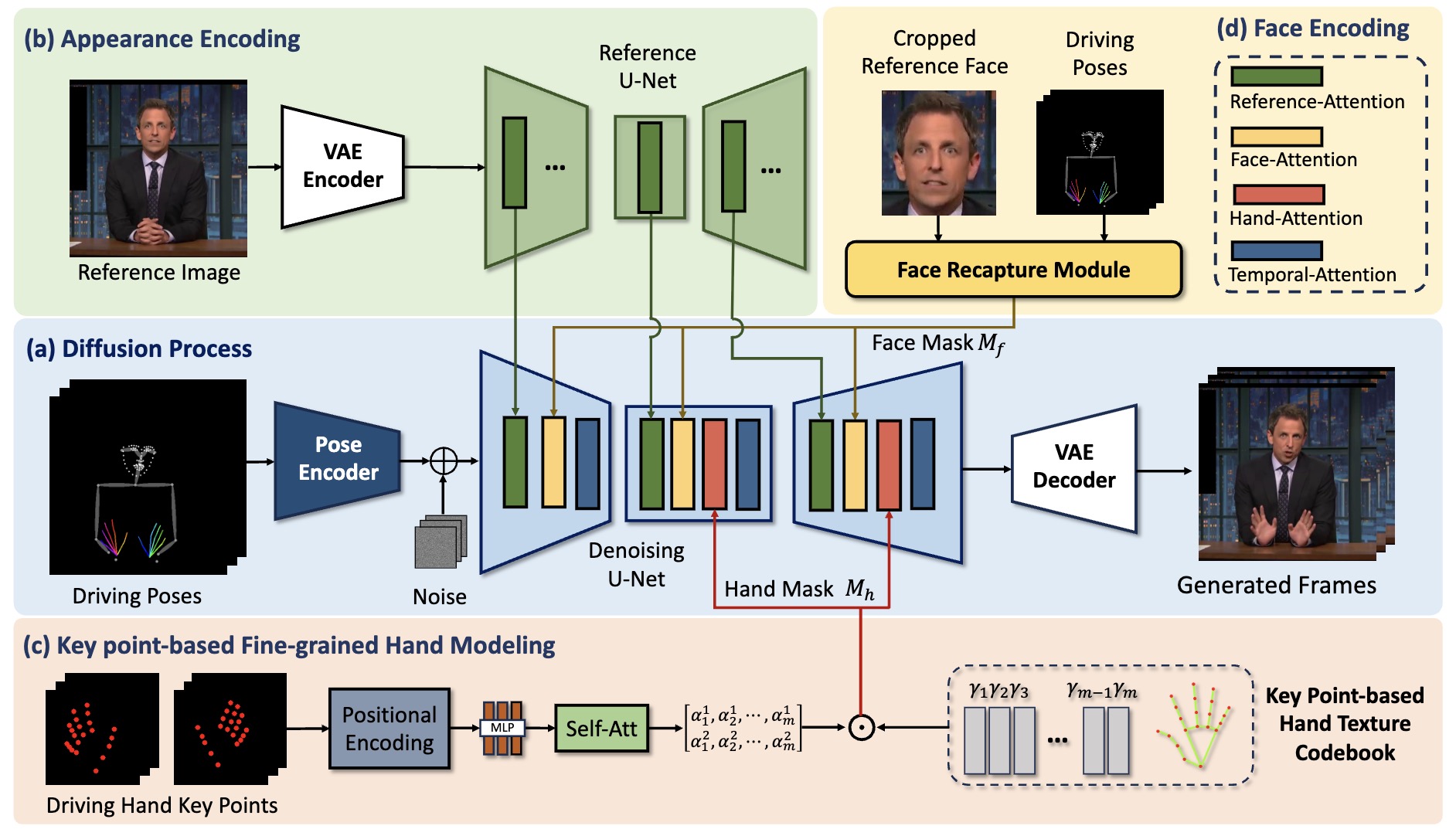
ShowMaker: Creating High-Fidelity 2D Human Video via Fine-Grained Diffusion Modeling
Quanwei Yang, Jiazhi Guan, Kaisiyuan Wang, Lingyun Yu, Wenqing Chu, Hang Zhou, ZhiQiang Feng, Haocheng Feng, Errui Ding, Jingdong Wang, Hongtao Xie.
- [CVIU 2024] Symmetrical Siamese Network for Pose-Guided Person Synthesis. Quanwei Yang, Lingyun Yu, Fengyuan Liu, Yun Song, Meng Shao, Guoqing Jin, Hongtao Xie.
- [ACM MM 2022] REMOT: A Region-to-Whole Framework for Realistic Human Motion Transfer. Quanwei Yang, Xinchen Liu, Wu Liu, HongtaoXie, Xiaoyan Gu, Lingyun Yu, Yongdong Zhang.
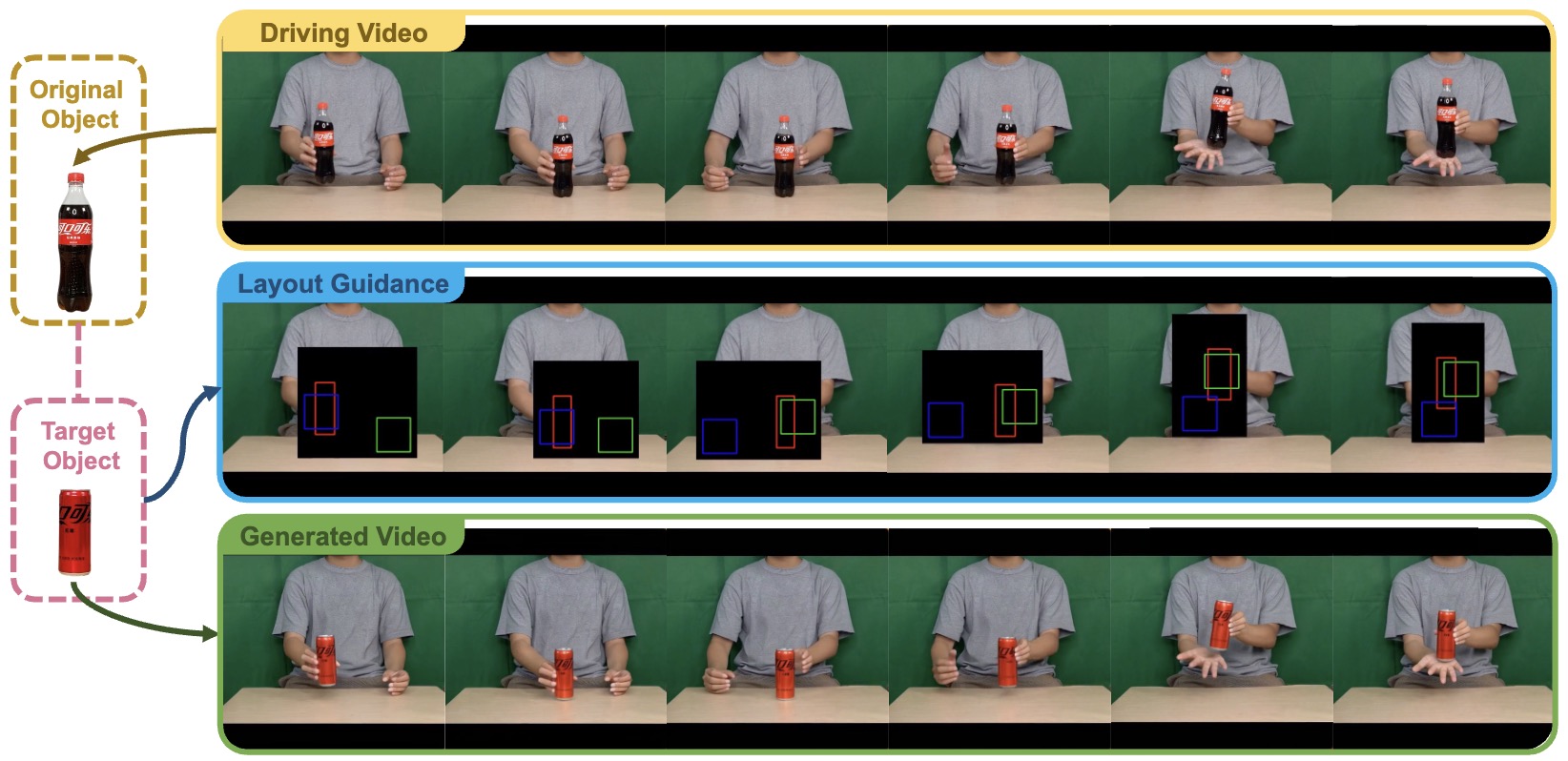
Re-HOLD: Video Hand Object Interaction Reenactment via adaptive Layout-instructed Diffusion Model
Yingying Fan, Quanwei Yang, Kaisiyuan Wang, Hang Zhou, Yingying Li, Haocheng Feng, Errui Ding, Yu Wu, Jingdong Wang
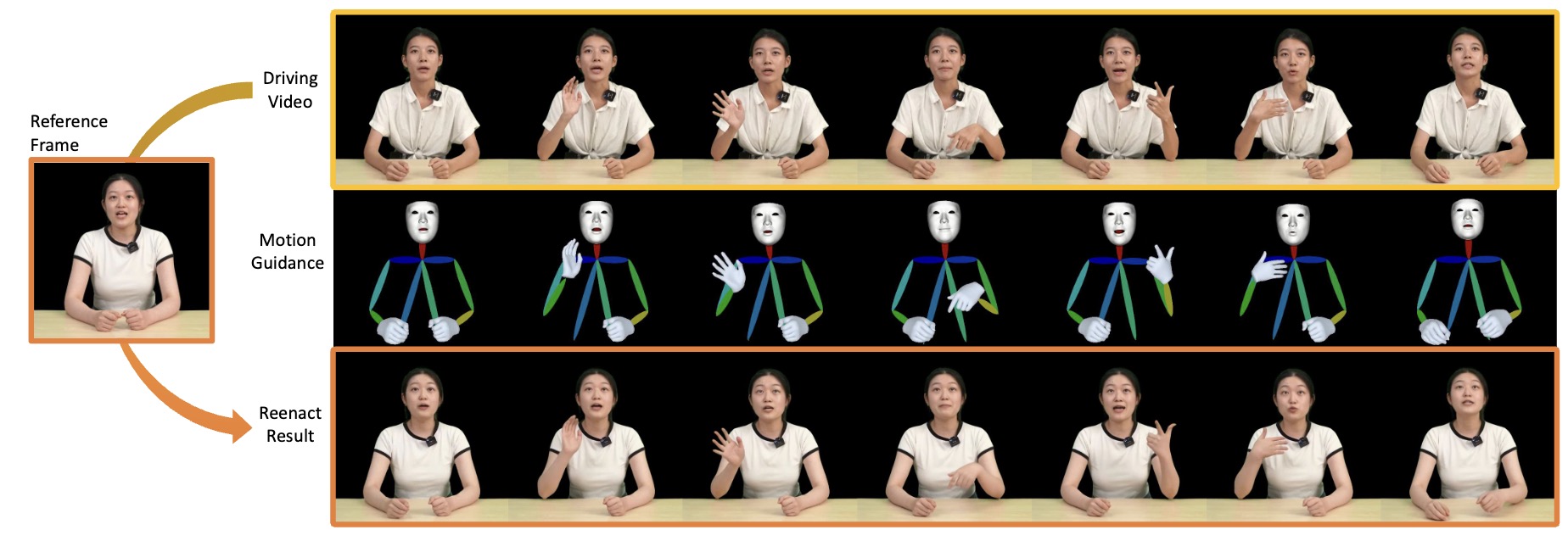
TALK-Act: Enhance Textural-Awareness for 2D Speaking Avatar Reenactment with Diffusion Model
Jiazhi Guan, Quanwei Yang, Kaisiyuan Wang, Hang Zhou, Shengyi He, Zhiliang Xu, Haocheng Feng, Errui Ding, Jingdong Wang, Hongtao Xie, Youjian Zhao, Ziwei Liu.
- [TMM 2024] High Fidelity Face Swapping via Facial Texture and Structure Consistency Mining. Fengyuan Liu, Lingyun Yu, Quanwei Yang, Meng Shao, Hongtao Xie.
- [CGF 2025] THGS: Lifelike Talking Human Avatar Synthesis from Monocular Video via 3D Gaussian Splatting. Chuang Chen, Lingyun Yu, Quanwei Yang, Aihua Zheng, Hongtao Xie.
- [Neurocomputing 2025] TalkingAvatar: Learning 3D Talking Human Avatar via NeRF. Lingyun Yu, Chuang Chen, Chuanbin Liu, Wu Liu, Quanwei Yang, Yizhi Liu, Meng Shao.
- [ICCV 2025] Forensic-MoE: Exploring Comprehensive Synthetic Image Detection Traces with Mixture of Experts. Mingqi Fang, Ziguang Li, Lingyun Yu, Quanwei Yang, Hongtao Xie, Yongdong Zhang.
- [CVPR 2025] AudCast: Audio-Driven Human Video Generation by Cascaded Diffusion Transformers. Jiazhi Guan, Kaisiyuan Wang, Zhiliang Xu, Quanwei Yang, Yasheng SUN, Shengyi He, Borong Liang, Yukang Cao, Yingying Li, Haocheng Feng, Errui Ding, Jingdong Wang, Youjian Zhao, Hang Zhou, Ziwei Liu. Project Page
- [ACM MM 2023] High Fidelity Face Swapping via Semantics Disentanglement and Structure Enhancement. Fengyuan Liu, Lingyun Yu, Hongtao Xie, Chuanbin Liu, Zhiguo Ding, Quanwei Yang, Yongdong Zhang.
🎖 Honors and Awards
- 2025.10, National Scholarship for Doctoral Students
- 2025.07, Baidu Outstanding intern
- 2022.09, Longhu scholarship of the University of Science and Technology of China
- 2020.07, Outstanding Graduate of Xidian University
- 2019.08, Meritorious Winner in the Mathematical Contest in Modeling for College students, USA
- 2018.10, CASC scholarship of China Aerospace Science and Technology Corporation
📖 Educations
- 2020.09 - 2026.06 (now), Ph.D., Information and Communication Engineering, University of Science and Technology of China.
- 2016.08 - 2020.06, Bachelor’s degree, Intelligent Science and Technology. Xidian University,
💻 Internships
- 2023.11 - now, VIS, Baidu, China.
- 2021.10 - 2023.04, JD Explore Academy, China.
- 2020.07 - 2021.07, MMU, Kuaishou, China.